How MIRE Works
Dhananjaya Jayasundara, Heng Zhao, Demetrio Labate, Vishal M. Patel
Johns Hopkins University • University of Houston
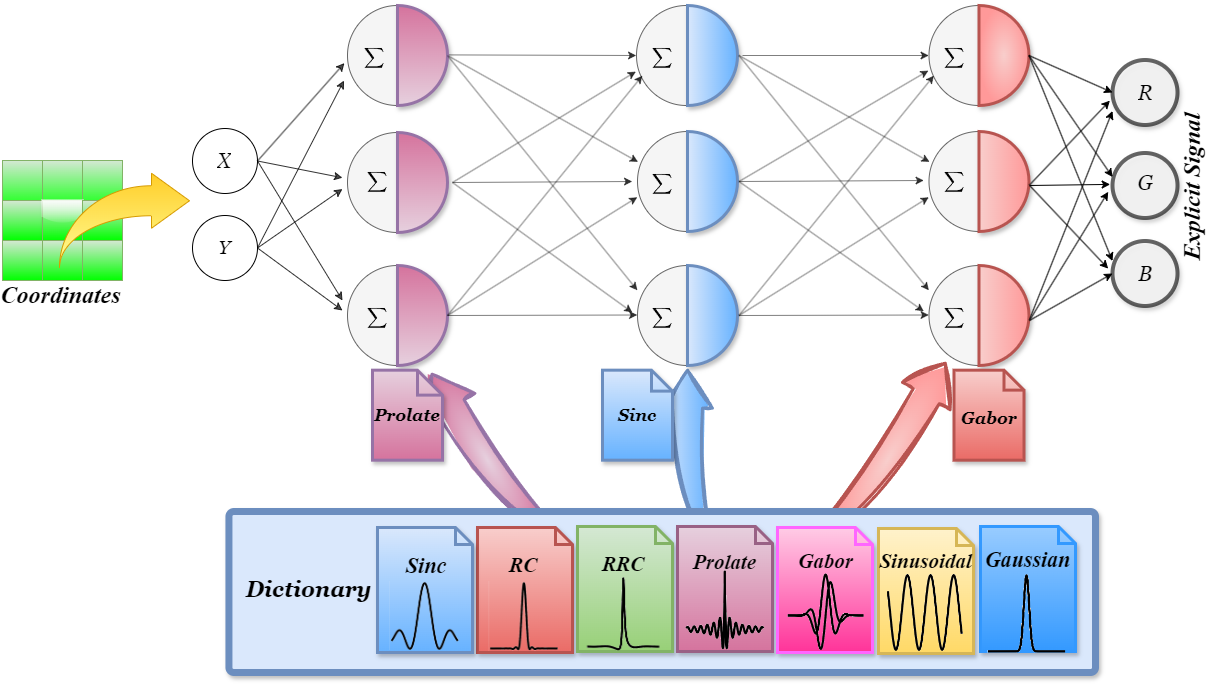
Implicit Neural Representations (INRs) are continuous function learners for conventional digital signal representations. With the aid of positional embeddings and/or exhaustively fine-tuned activation functions, INRs have surpassed many limitations of traditional discrete representations. However, existing works use a fixed activation function throughout the INR, which limits adaptability to the signal. We hypothesize that this restricts representation power and generalization. We introduce MIRE, a method to match activation functions per layer using dictionary learning. Our activation dictionary includes Raised Cosines (RC), Root Raised Cosines (RRC), Prolate Spheroidal Wave Function (PSWF), Sinc, Gabor Wavelet, Gaussian, and Sinusoidal. MIRE improves INR performance across tasks such as image representation, inpainting, 3D shape representation, novel view synthesis, and super-resolution—while removing the need for exhaustive activation parameter searches.
Coming soon...